[번역] React Query and React Context
![[번역] React Query and React Context](https://tkdodo.eu/blog/static/9b27d274802aec07ecc7e854423c460b/bbe0c/context.jpg)
이 글은 TkDodo의 React Query and React Context 를 번역한 글입니다.
React Query의 가장 좋은 특징 중 하나는 컴포넌트 트리에서 원하는 곳 어디에서나 쿼리를 사용할 수 있다는 것입니다: <ProductTable> 컴포넌트는 필요한 곳에 같은 위치에 있는 자체 데이터를 가져올 수 있습니다.
function ProductTable() {
const productQuery = useProductQuery();
if (productQuery.data) {
return <table>...</table>;
}
if (productQuery.isError) {
return <ErrorMessage error={productQuery.error} />;
}
return <SkeletonLoader />;
}제게는 이것이 ProductTable 을 분리되고 독립적으로 만들기 때문에 훌륭합니다 : 그것은 자신의 종속성 인 Product Data를 읽는 책임이 있습니다. 이미 캐시에 있다면 좋습니다. 그렇지 않다면, 우리는 그것을 fetching할 것입니다. 그리고 React Server Components에서도 유사한 패턴이 나타나는 것을 볼 수 있습니다. 또한 구성 요소 내에서 바로 데이터를 가져올 수 있습니다. 더 이상 상태 저장 구성 요소와 상태 비저장 또는 스마트 구성 요소와 멍청한 구성 요소 간의 임의적인 분할이 없습니다.
따라서 필요한 구성 요소에서 바로 데이터를 가져올 수 있다는 것은 매우 유용합니다. 말 그대로 ProductTable 구성 요소를 가져와서 앱의 아무 곳으로나 이동할 수 있으며 작동합니다. 이 구성 요소는 변경에 매우 탄력적이기 때문에 #10: React Query as a State Manager 및 #21: Thinking in React Query 에서 필요할 때마다 (custom hook을 통해) 쿼리에 직접 액세스하는 것을 옹호하는 주된 이유입니다.
하지만 그것은 은색 총알이 아닙니다 - 그것은 절충안이 있습니다. 하루가 끝나면 모든 것이 트레이드 오프이기 때문에 이것은 놀라운 일이 아닙니다. 하지만 여기서 정확히 무엇을 트레이드 하고 있을까요?
Being self-contained
구성 요소가 자율적이려면 쿼리 데이터를 (아직) 사용할 수 없는 경우, 특히 로딩 및 오류 상태를 처리해야 합니다. <ProductTable> 구성 요소에는 큰 문제가 되지 않는데, 처음 로드될 때 실제로 <SkeletonLoader />를 표시하는 경우가 많기 때문입니다.
그러나 쿼리의 일부에서 일부 정보를 읽고자 하는 다른 상황이 많이 있으며, 여기서 쿼리가 이미 트리 위쪽에서 사용되었음을 알고 있습니다. 예를 들어 로그인한 사용자에 대한 정보가 포함된 userQuery가 있을 수 있습니다.
export const useUserQuery = (id: number) => {
return useQuery({
queryKey: ['user', id],
queryFn: () => fetchUserById(id),
})
}
export const useCurrentUserQuery = () => {
const id = useCurrentUserId()
return useUserQuery(id)
}구성 요소 트리에서 이 쿼리를 사용하여 로그인한 사용자가 어떤 사용자 권한을 가지고 있는지 확인하고 실제로 페이지를 볼 수 있는지 여부를 추가로 결정할 수 있습니다. 페이지의 모든 곳에서 원하는 필수 정보입니다.
이제 트리 아래로 더 내려가면 useCurrentUserQuery 훅에서 얻을 수 있는 userName을 표시하려는 구성 요소가 있을 수 있습니다.
function UserNameDisplay() {
const { data } = useCurrentUserQuery();
return <div>User: {data.userName}</div>;
}물론 TypeScript는 데이터가 잠재적으로 undefined 이므로 허용하지 않습니다. 그러나 우리는 더 잘 알고 있습니다 - 우리의 상황에서는 쿼리가 이미 트리 위로 시작되지 않으면 UserNameDisplay 가 렌더링되지 않기 때문에 undefined일 수 없습니다.
약간 딜레마가 있습니다. 정의될 것을 알기 때문에 여기서 TS를 종료하고 data!.userName을 사용해야 할까요? 아니면 안전을 위해 data?.userName(여기서는 가능하지만 다른 상황에서는 쉽지 않을 수 있음)을 사용할까요? 아니면 if (!data) return null과 같은 가드를 추가할까요? 아니면 useCurrentUserQuery를 호출하는 25곳 모두에 적절한 로딩과 오류 처리를 추가해야 할까요?
솔직히 말해서 저는 이 모든 방법이 차선책이라고 생각합니다. 제가 아는 한 “절대 일어나지 않을” 검사로 코드베이스를 가득 채우고 싶지 않거든요. 하지만 (평소처럼) TS가 옳기 때문에 TypeScript를 무시하고 싶지도 않습니다.
An implicit dependency
문제는 암시적 종속성이 있다는 사실에서 비롯됩니다: 애플리케이션 구조에 대한 지식으로 머릿속에만 존재하지만 코드 자체에는 보이지 않는 종속성입니다.
정의되지 않은 데이터를 확인할 필요 없이 useCurrentUserQuery를 안전하게 호출할 수 있다는 것을 알고 있지만 정적 분석으로는 이를 확인할 수 없습니다. 동료들은 이 사실을 모를 수도 있습니다. 저 자신도 3개월 후에는 이 사실을 모를 수도 있습니다.
가장 위험한 부분은 지금은 사실이지만 미래에는 더 이상 사실이 아닐 수도 있다는 것입니다. 캐시에는 사용자 데이터가 없을 수도 있고, 이전에 다른 페이지를 방문한 경우와 같이 조건부로 캐시에는 사용자 데이터가 있을 수도 있는 앱의 어딘가에 UserNameDisplay의 다른 인스턴스를 렌더링할 수 있습니다.
이는 <ProductTable>컴포넌트와는 정반대입니다: 변경에 탄력적으로 대응하는 대신 리팩터링에 오류가 발생하기 쉽습니다. 서로 관련이 없어 보이는 컴포넌트 몇 개를 이동했다고 해서 UserNameDisplay 컴포넌트가 깨지는 일은 없을 것입니다.
Make it explicit
물론 해결책은 의존성을 명시적으로 만드는 것입니다. 그리고 이보다 더 좋은 방법은 없습니다:
React Context
리액트 컨텍스트에 대한 오해가 많으니 바로잡아 보겠습니다: 아니요, React Context는 상태 관리자가 아닙니다. useState 또는 useReducer와 결합하면 상태 관리를 위한 겉보기에는 좋은 솔루션이 될 수 있지만, 저는 이런 상황에서 너무 많은 화상을 입었기 때문에 이 접근 방식을 좋아하지 않습니다:
🕵️We’ve fixed a huge performance problem this week by moving useState + context over to zustand. It was the same amount of code. The lib is < 1kb.
⚛️Don’t use context for state management. Use it for dependency injection only. The right tool for the job! https://t.co/dlDiCTv4Fw
— Dominik 🔮 (@TkDodo) February 19, 2022
따라서 전용 도구를 사용하는 것이 더 나을 수 있습니다. Redux의 유지 관리자이면서 매우 긴 블로그 게시물을 작성하는 마크 에릭슨 이 이 주제에 대한 좋은 글을 작성했습니다: Blogged Answers: Why React Context is Not a “State Management” Tool (and Why It Doesn’t Replace Redux) .
제 트윗에 이미 언급되어 있습니다: 리액트 컨텍스트는 의존성 주입 도구입니다. 이를 사용하면 컴포넌트가 작동하는 데 필요한 “사물”을 정의할 수 있으며, 모든 부모는 해당 정보를 제공할 책임이 있습니다.
이는 여러 레이어를 통해 소품을 전달하는 프로세스인 프롭 드릴링과 개념적으로 동일합니다. 컨텍스트를 사용하면 일부 값을 가져와 자식에게 소품으로 전달할 수 있지만 몇 개의 레이어를 생략할 수 있다는 점을 제외하면 동일한 작업을 수행할 수 있습니다:
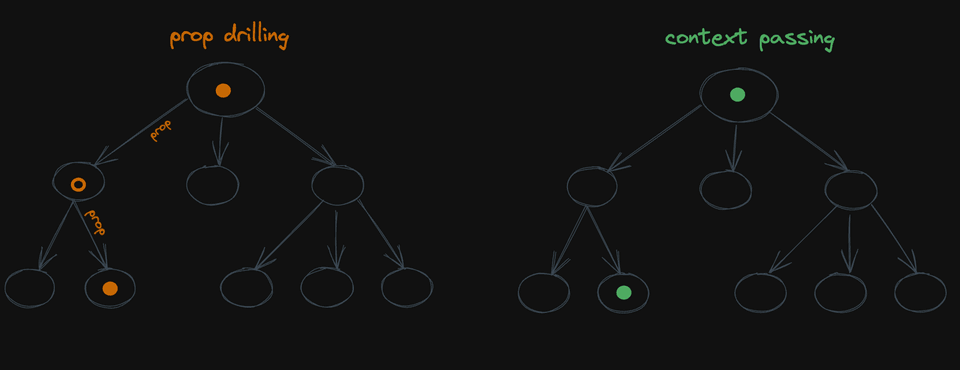
컨텍스트를 사용하면 중간자를 건너뛸 수 있습니다. useCurrentUserQuery 예제에서는 이러한 의존성을 명시적으로 만드는 데 도움이 될 수 있습니다: 데이터 가용성 검사를 건너뛰고 싶은 모든 컴포넌트에서 useCurrentUserQuery를 직접 읽는 대신, React 컨텍스트에서 읽습니다. 그리고 그 컨텍스트는 실제로 첫 번째 검사를 수행하는 부모에 의해 채워집니다:
const CurrentUserContext = React.createContext<User | null>(null)
export const useCurrentUserContext = () => {
return React.useContext(CurrentUserContext)
}
export const CurrentUserContextProvider = ({
children,
}: {
children: React.ReactNode
}) => {
const currentUserQuery = useCurrentUserQuery()
if (currentUserQuery.isPending) {
return <SkeletonLoader />
}
if (currentUserQuery.isError) {
return <ErrorMessage error={currentUserQuery.error} />
}
return (
<CurrentUserContext.Provider value={currentUserQuery.data}>
{children}
</CurrentUserContext.Provider>
)
}여기서는 currentUserQuery를 가져와서 결과 데이터를 (로딩 및 오류 상태를 미리 제거하여) 존재하는 경우 React 컨텍스트에 넣습니다. 그러면 그 컨텍스트에서 안전하게 자식 컴포넌트(예: UserNameDisplay 컴포넌트)에서 읽을 수 있습니다:
function UserNameDisplay() {
const data = useCurrentUserContext();
return <div>User: {data.username}</div>;
}이를 통해 암시적 종속성(트리의 앞부분에서 데이터를 가져온 것을 알고 있음)을 명시적으로 만들었습니다. 누군가가 UserNameDisplay를 볼 때마다 CurrentUserContextProvider에서 데이터를 제공해야 한다는 것을 알 수 있습니다. 이는 리팩토링할 때 염두에 둘 수 있는 사항입니다. 프로바이더가 렌더링되는 위치를 변경하면 해당 컨텍스트를 사용하는 모든 자식에도 영향을 미친다는 것을 알 수 있습니다. 쿼리는 일반적으로 전체 앱에서 전역적이며 데이터가 존재할 수도 있고 존재하지 않을 수도 있기 때문에 컴포넌트가 쿼리를 사용할 때는 알 수 없는 사항입니다.
Pleasing TypeScript
타입스크립트는 여전히 이를 별로 좋아하지 않을 것입니다. 왜냐하면 React Context는 컨텍스트의 기본값을 제공하는 프로바이더 없이도 작동하도록 설계되었고, 우리의 경우 그 기본값은 null이기 때문입니다. 프로바이더 외부에 있는 상황에서는 useCurrentUserContext가 작동하지 않기를 바라기 때문에 사용자 정의 훅에 불변성을 추가할 수 있습니다:
export const useCurrentUserContext = () => {
const currentUser = React.useContext(CurrentUserContext);
if (!currentUser) {
throw new Error('CurrentUserContext: No value provided');
}
return currentUser;
};이 메서드를 사용하면 실수로 잘못된 위치에서 useCurrentUserContext에 액세스하는 경우 오류 메시지와 함께 빠르게 실패할 수 있습니다. 그리고 이를 통해 TypeScript는 사용자 정의 훅에 대한 사용자 값을 유추하므로 안전하게 사용하고 프로퍼티에 액세스할 수 있습니다.
State Syncing
이렇게 생각할 수도 있습니다: React 쿼리에서 하나의 값을 복사하여 다른 상태 배포 방법에 넣는 것이 “상태 동기화”가 아닌가요? 정답은 ‘아니오’입니다: 아니요, 그렇지 않습니다! 진실의 단일 출처는 여전히 쿼리입니다. 쿼리에 항상 최신 데이터가 반영되는 공급자 외에는 컨텍스트 값을 변경할 수 있는 방법이 없습니다. 여기서는 아무것도 복사되지 않으며 동기화에서 벗어날 수 없습니다. React 쿼리에서 자식 컴포넌트로 data를 프롭으로 전달하는 것도 “상태 동기화”가 아니며, 컨텍스트는 프롭 드릴링과 유사하므로 이 역시 “상태 동기화”가 아닙니다.
Request Waterfalls
단점이 없는 것은 없으며, 이 기술 역시 마찬가지입니다. 특히 컴포넌트 트리가 프로바이더에서 렌더링을 중지(“일시 중단”)하기 때문에 하위 컴포넌트가 렌더링되지 않고 관련 없는 경우에도 네트워크 요청을 실행할 수 없기 때문에 네트워크 워터폴이 발생할 수 있습니다.
저는 주로 하위 트리에 필수적인 데이터에 이 접근 방식을 고려합니다: 사용자 정보가 좋은 예입니다. 해당 데이터가 없으면 무엇을 렌더링할지 알 수 없기 때문입니다.
Suspense
Suspense에 대해 이야기하자면, 예, React Suspense로 비슷한 아키텍처를 구현할 수 있으며, 동일한 단점인 잠재적인 요청 워터폴( #17: Seeding the Query Cache 에서 이미 설명한 바 있습니다)이 있습니다.
한 가지 문제는 현재 주요 버전(v4)에서는 쿼리를 비활성화하고 실행되지 않도록 하는 방법이 여전히 존재하기 때문에 쿼리에 suspense: true를 사용하면 좁은 data를 입력할 수 없다는 것입니다. 그러나 v5부터는 컴포넌트가 렌더링되면 데이터가 정의되도록 보장하는 명시적인 useSuspenseQuery 훅이 있습니다. 이를 통해 할 수 있습니다:
function UserNameDisplay() {
const { data } = useSuspenseQuery(...)
return <div>User: {data.username}</div>
}이를 사용하면 TypeScript도 만족할 것입니다. 🎉